[Восстановление данных, Облачные вычисления, Резервное копирование] Hystax Cloud Migration: скачем по облакам
Автор
Сообщение
news_bot ®
Стаж: 8 лет 4 месяца
Сообщений: 27286
Одним из молодых игроков на рынке решений Disaster Recovery является компания Hystax – российский стартап 2016 года. Поскольку тема аварийного восстановления очень популярна, и на рынке крайне высокая конкуренция, стартап решил сфокусироваться на миграции между различными облачными инфраструктурами. Продукт, позволяющий организовать простую и быструю миграцию в облако, был бы очень полезен и клиентам компании «Онланта» - пользователям Oncloud.ru. Так я и познакомился с Hystax и начал тестировать его возможности. А что из этого получилось, расскажу в этой статье.

Основной фишкой Hystax являются его широкая функциональность по поддержке различных платформ виртуализации, гостевых ОС и облачных сервисов, что даёт возможность переносить ваши рабочие нагрузки откуда угодно и куда угодно.
Это позволяет создавать не только DR-решения для повышения отказоустойчивости сервисов, но и оперативно, гибко мигрировать ресурсы между различными площадками и гиперскейлерами для повышения экономии средств и выбора наилучшего решения под конкретный сервис в данный момент. Помимо платформ, перечисленных на заглавной картинке, компания также активно сотрудничает и с российскими облачными провайдерами: Yandex.Cloud, КРОК «Облачные сервисы», Mail.ru и многими другими. Также стоит отметить, что в 2020 году у компании появился R&D центр, располагающийся в Сколково.
Выбор одного решения большим количеством игроков на рынке говорит о хорошей ценовой политике и высокой применимости продукта, что мы и решили проверить на практике.
Итак, наша тестовая задача будет состоять из миграции с моей тестовой площадки VMware и физических машин на площадку провайдера также под управлением VMware. Да, есть множество решений, которые могут осуществить подобную миграцию, но мы рассматриваем Hystax как универсальное средство, а протестировать миграцию во всех возможных сочетаниях — просто нереальная задача. Да и облако Oncloud.ru построено именно на VMware, поэтому данная платформа как целевая интересует нас в большей степени. Далее я опишу основной принцип работы, который в целом не зависит от платформы, и VMware с любой стороны может быть заменена на платформу другого вендора.
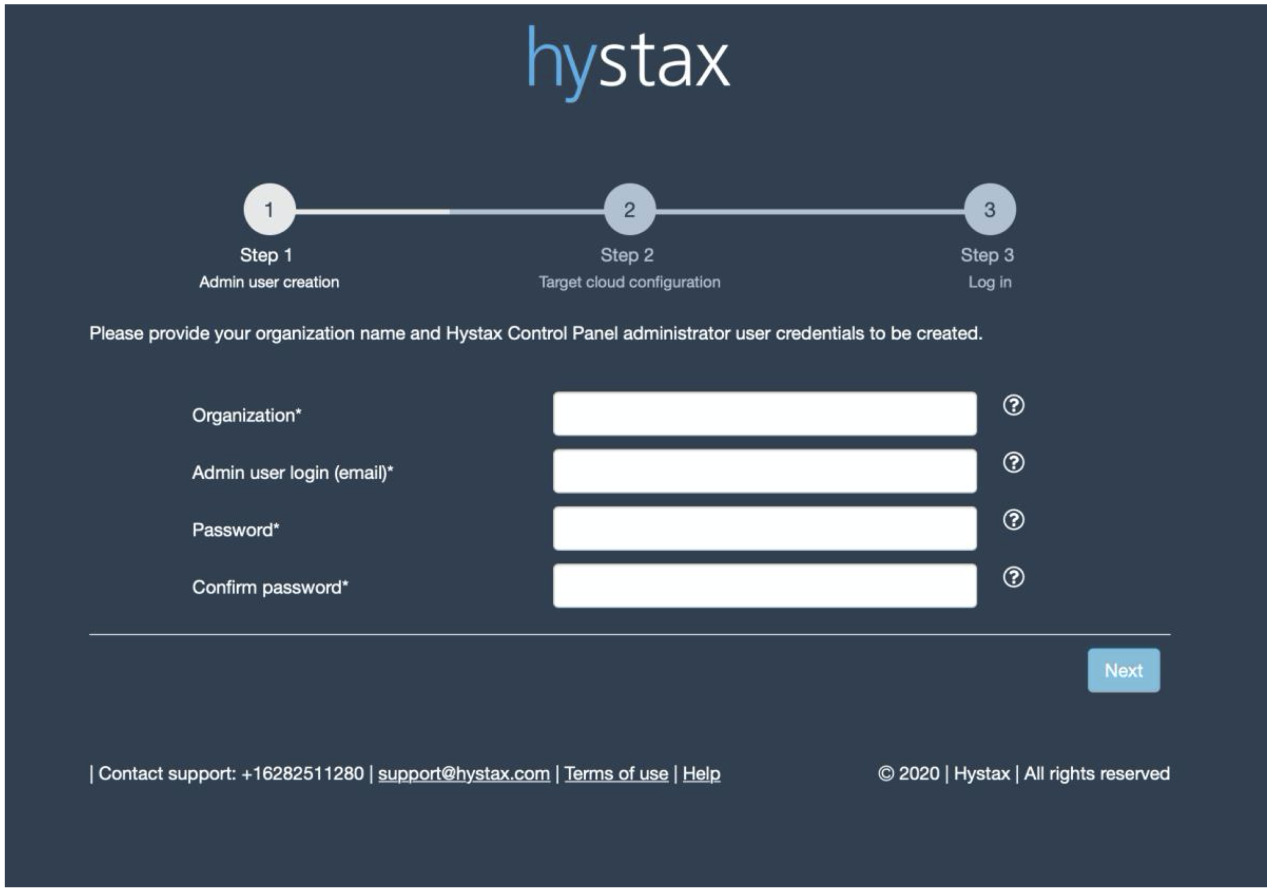
На первом этапе необходимо развернуть Hystax Acura, которая является панелью управления системы.

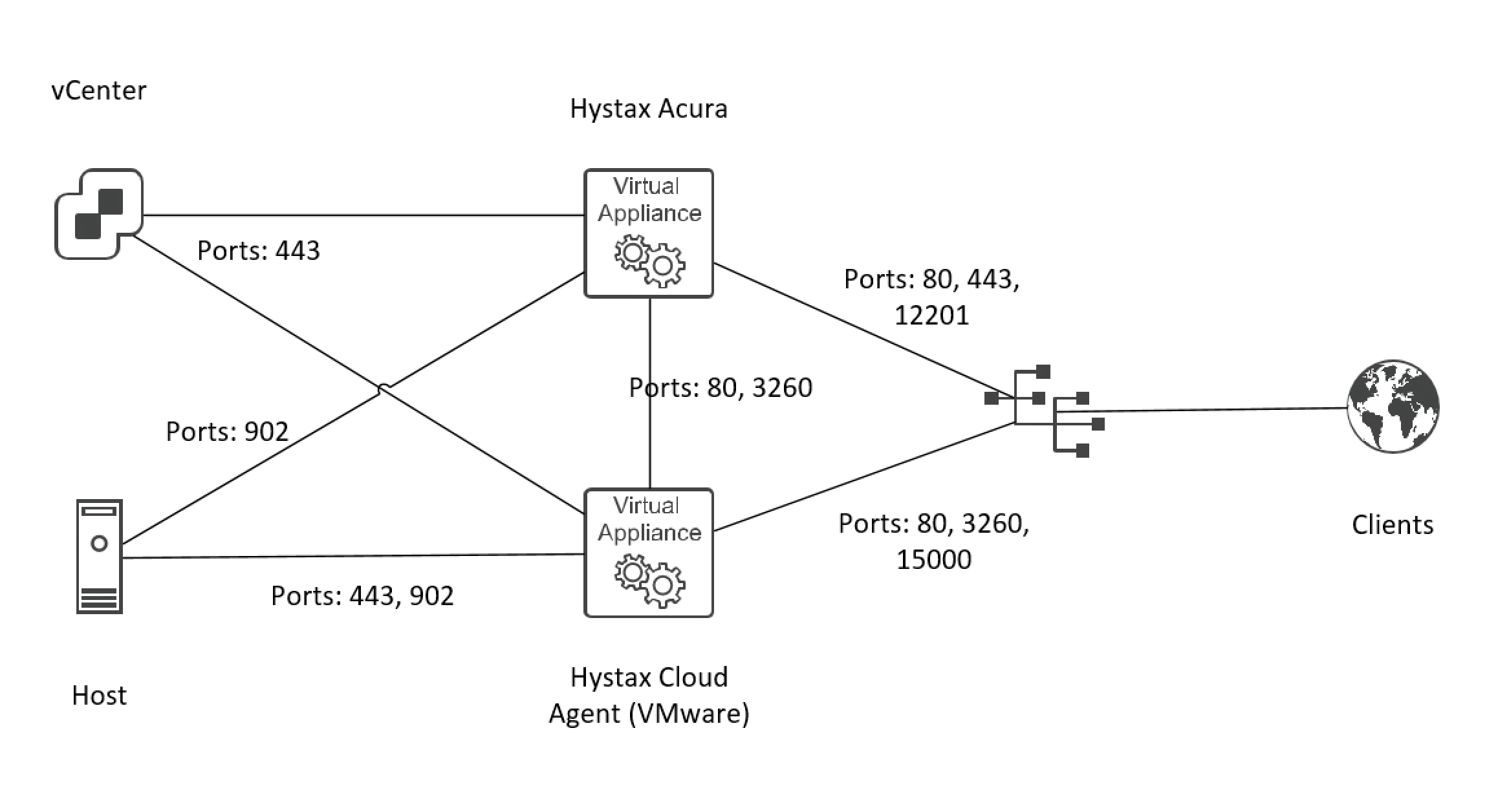
Она разворачивается из шаблона. Почему-то в нашем случае он был не совсем корректен и вместо рекомендуемых 8CPU, 16Gb разворачивался с вдвое меньшими ресурсами. Поэтому нужно не забыть их изменить, иначе контейнерами инфраструктура внутри VM, на которой всё и построено, просто не запустится и портал будет недоступен. В Deployment requirements подробно описаны требуемые ресурсы, а также порты для всех компонентов системы.
И с заданием IP-адреса через шаблон также возникли трудности, так что меняли его из консоли. После этого можно перейти в веб-интерфейс админки и заполнить первоначальный мастер конфигурации.


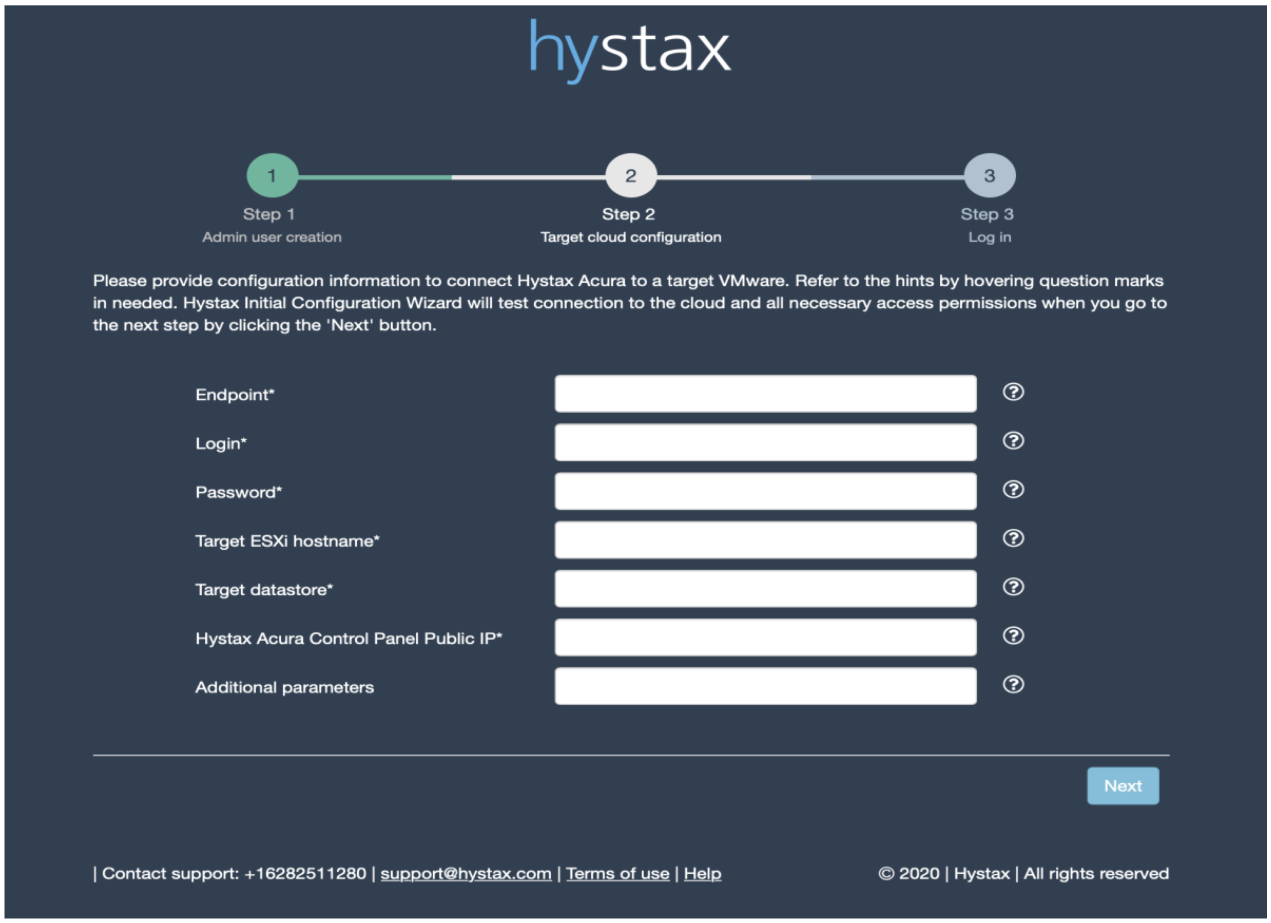
Endpoint – IP или FQDN нашего vCenter.
Login и Password – тут понятно.
Target ESXi hostname – один из хостов нашего кластера, на который будет производиться репликация.
Target datastore – один из датасторов нашего кластера, на который будет производится репликация.
Hystax Acura Control Panel Public IP – адрес, по которому будет доступна панель управления.
Требуется небольшое уточнение по хосту и датастору. Дело в том, что репликация Hystax работает на уровне хоста и датастора. Дальше я расскажу, каким образом можно для тенанта сменить хост и датастор, но проблема в другом. Hystax не поддерживает работу с ресурс пулами, т.е. реплика всегда будет происходить в корень кластера (во время написания этого материала ребята из Hystax выпустили обновлённую версию, где быстро внедрили мой feature request по поводу поддержки ресурс-пулов). Также не поддерживается и vCloud Director, т.е. если, как в моём случае, у тенанта нет админских прав на весь кластер, а только на конкретный ресурс-пул, и мы дали доступ к Hystax, то он сможет самостоятельно среплицировать и запустить эти ВМ, но он не сможет их увидеть в инфраструктуре VMware, к которой у него есть доступ и, соответственно, дальше управлять виртуальными машинами. Необходимо, чтобы администратор кластера переместил VM в нужный ресурсный пул или импортировал в vCloud Director.
Почему я так акцентирую внимание на этих моментах? Потому что, насколько мне понятна концепция продукта, заказчик должен иметь возможность самостоятельно реализовать любую миграцию или DR при помощи панели Acura. Но пока поддержка VMware немного отстаёт по своему уровню от поддержки того же OpenStack, где подобные механизмы уже реализованы.
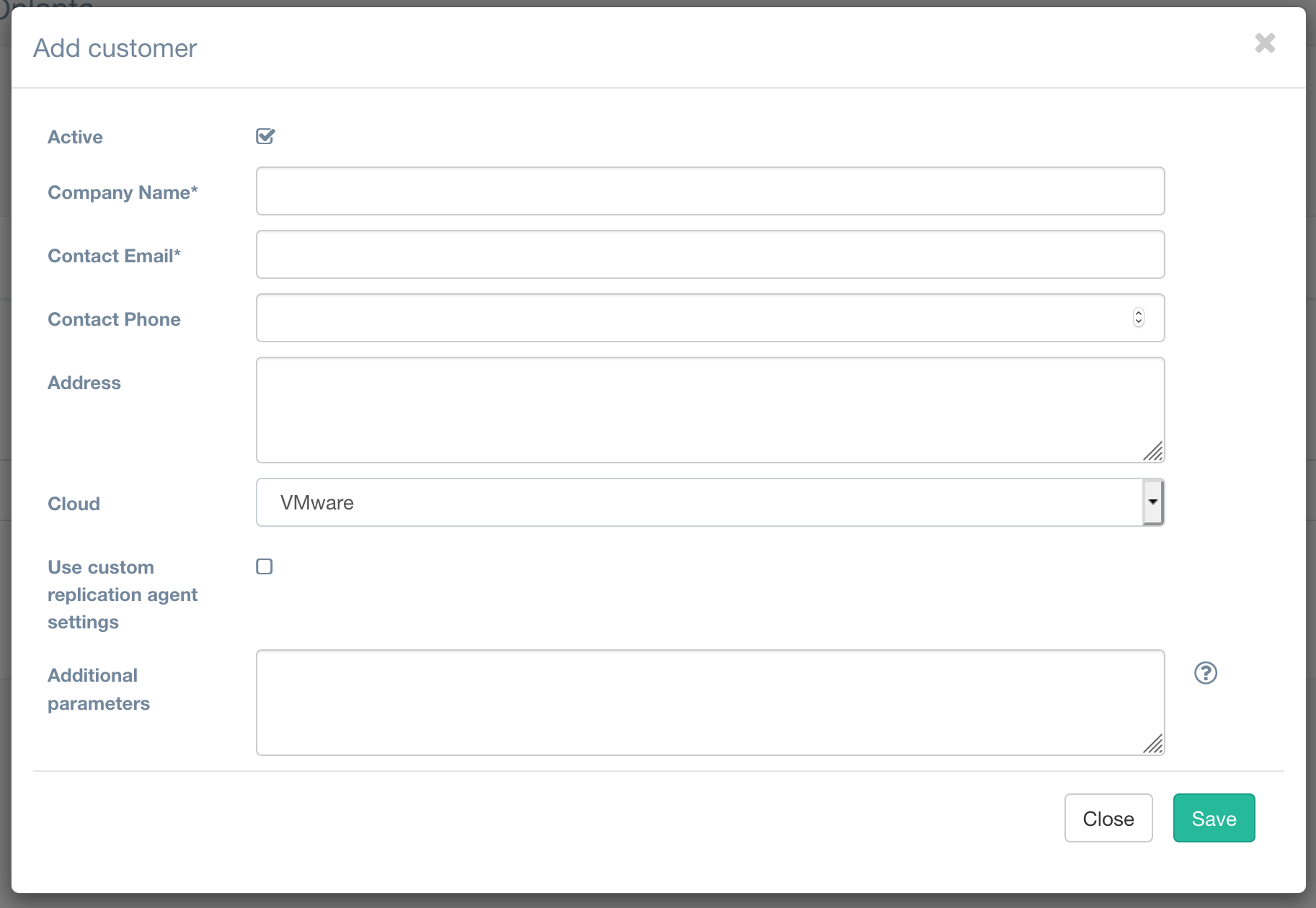
Но вернёмся к развёртыванию. Первым делом, после первоначальной настройки панели, нам необходимо создать первого тенанта в нашей системе.

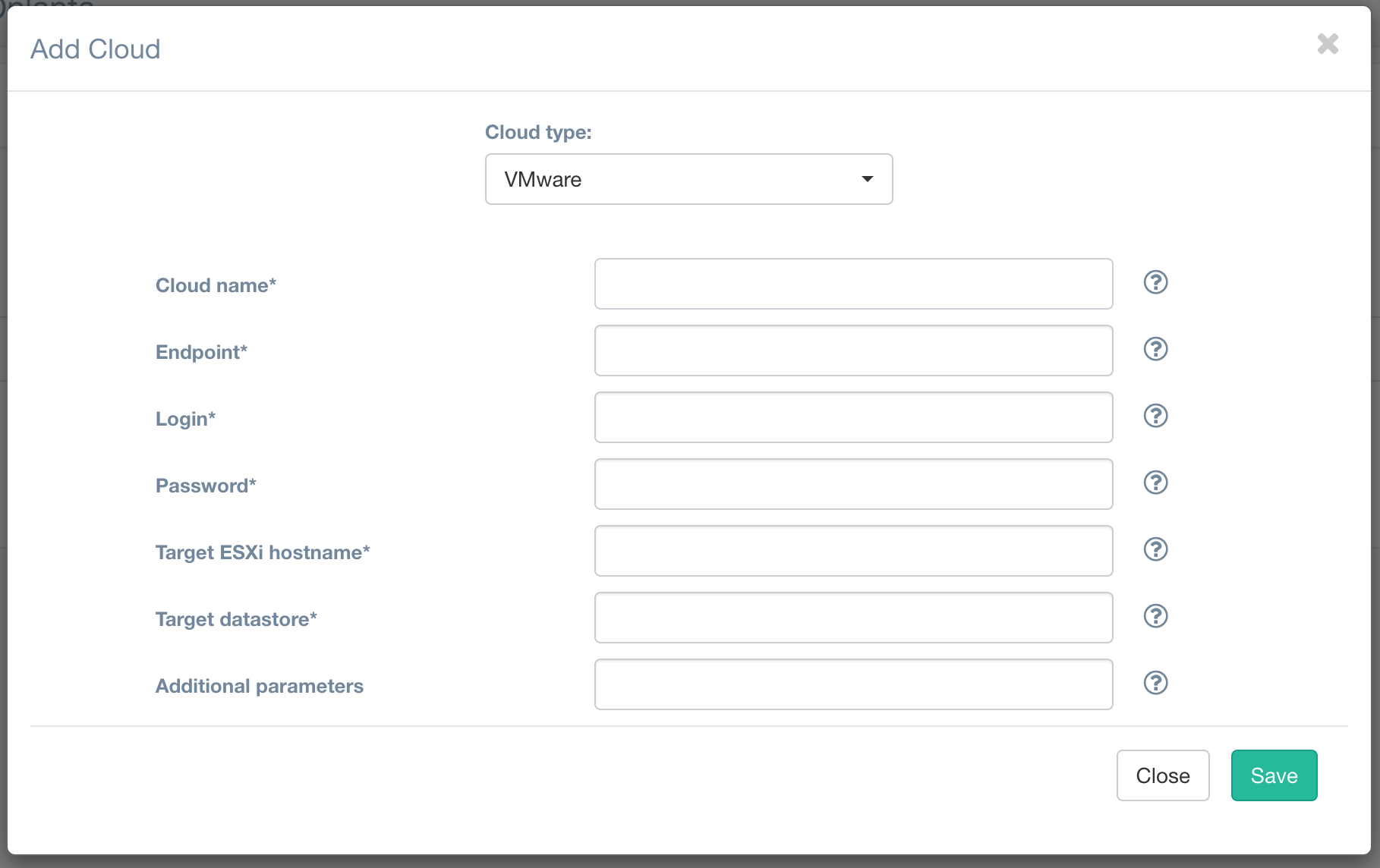
Все поля тут понятны, расскажу только про поле Cloud. У нас уже есть «дефолтное» облако, которое мы создали при первоначальном конфигурировании. Но если мы хотим иметь возможность класть каждый тенант на собственный датастор и в собственный ресурс-пул, мы можем это реализовать посредством создания отдельных облаков для каждого из наших заказчиков.

В форме добавления нового облака мы указываем те же параметры, что и при первоначальном конфигурировании (можем использовать даже тот же хост), указываем нужный для конкретного заказчика датастор, а теперь в дополнительных параметрах мы можем уже индивидуально указать необходимый ресурс-пул {«resource_pool»: «YOUR_POOL_NAME»}
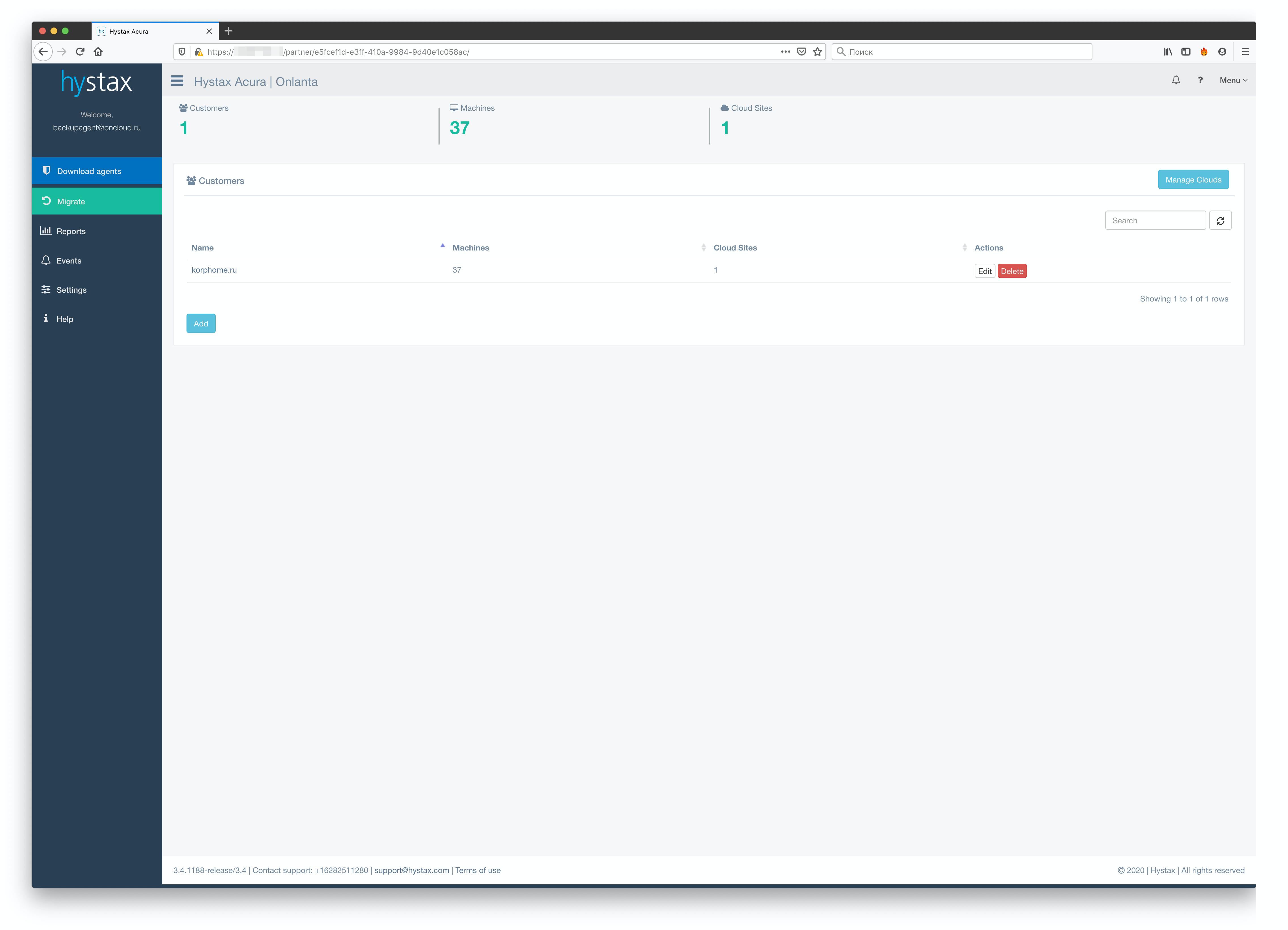
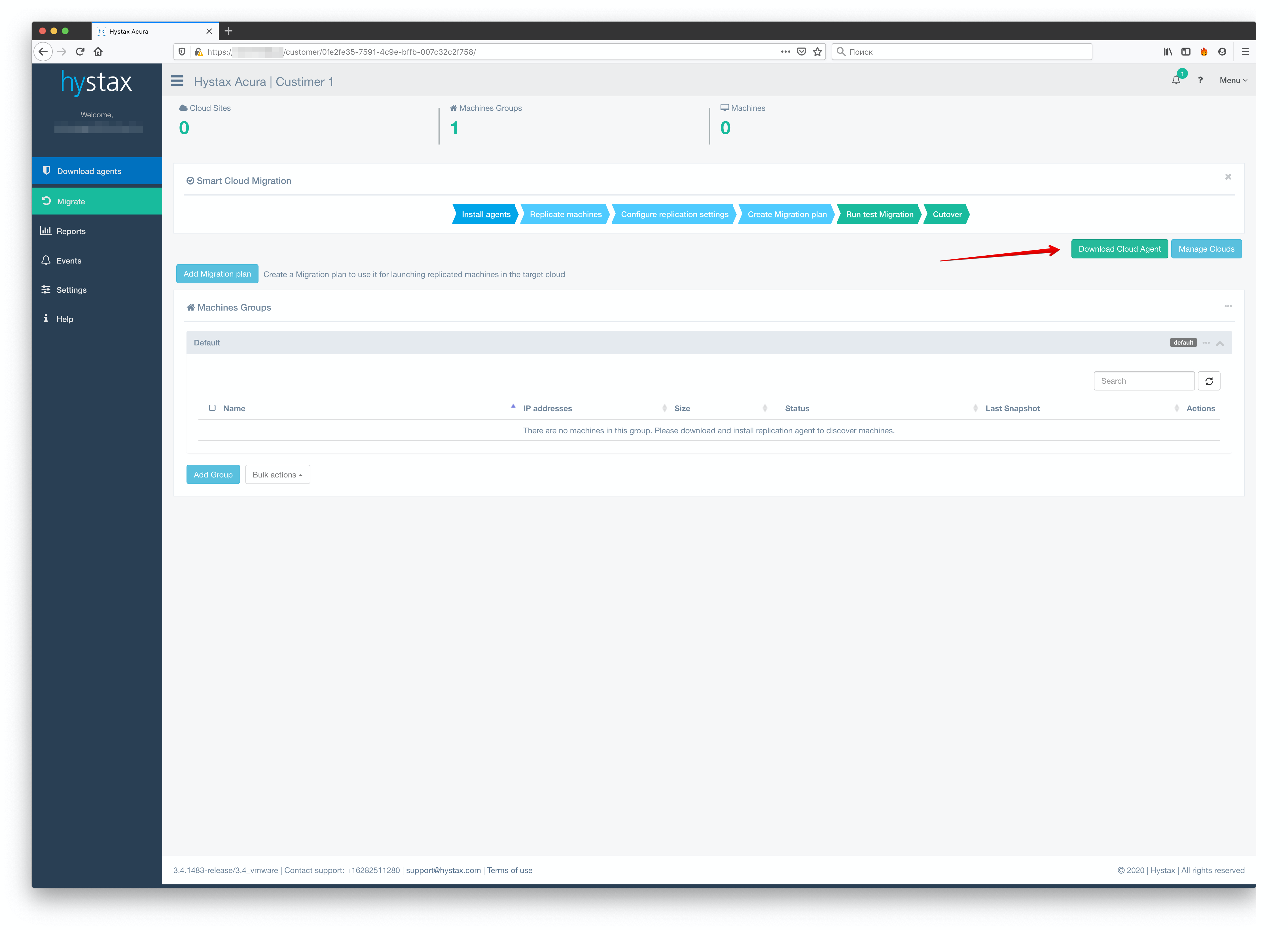
Как вы могли заметить, в форме создания тенанта нет ничего про выделение ресурсов или какие-то квоты – ничего этого в системе нет. Ограничить тенанта в количестве одновременных реплик, количестве машин для репликации или по какими-то иным параметрам нельзя. Итак, мы создали первого тенанта. Теперь есть не совсем логичная, но обязательная вещь – установка Cloud-агента. Нелогична она, поскольку агент скачивается на странице конкретного кастомера.

При этом он не привязывается к созданному тенанту, и через него будут работать все наши заказчики (или через несколько, если мы их задеплоим). Один агент поддерживает 10 одновременных сессий. За одну сессию считается одна машина. При этом не важно, какое у неё количество дисков. На сегодняшний день механизма для масштабирования агентов в самой Acura под VMware нет. Есть и ещё один неприятный момент – мы не имеем возможности из панели Acura посмотреть на «утилизацию» этого агента, чтобы сделать вывод, нужно ли нам развернуть ещё или текущей инсталляции достаточно. В итоге стенд выглядит следующим образом:

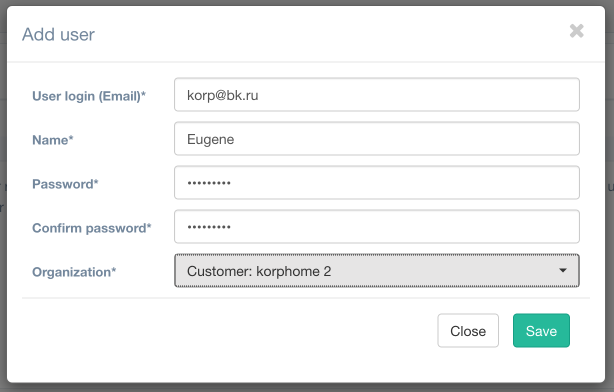
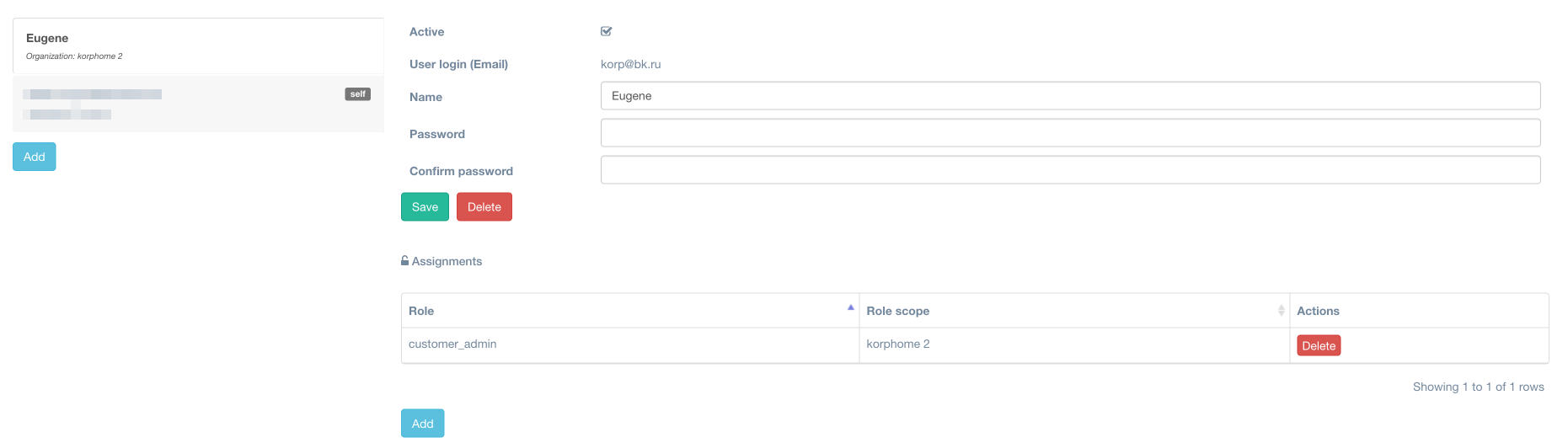
Следующим этапом для доступа к порталу нашего кастомера необходимо создать учётную запись (а предварительно ещё и роль, которая будет применяться к данному пользователю).


Теперь наш заказчик может пользоваться порталом самостоятельно. Всё, что ему необходимо сделать, – скачать с портала агентов и установить на своей стороне. Существует три вида агентов: Linux, Windows и VMware.

Первые два ставятся на физику или на виртуальные машины на любом гипервизоре, отличном от VMware. Здесь не требуется дополнительно ничего конфигурировать, агент скачивается и уже знает, куда нужно стучаться, и буквально через минуту машину будет видно в панели Acura. С агентом VMware ситуация чуть более сложная. Проблема в том, что агент для VMware также скачивается с портала уже подготовленный и имеющий в себе необходимую конфигурацию. Но агенту VMware помимо знания о нашем портале Acura необходимо знать ещё и о системе виртуализации, на которой он будет развёрнут.

Собственно, эти данные система и попросит нас указать при первом скачивании агента VMware. Проблема в том, что в наш век всеобщей любви к безопасности далеко не все захотят указывать свой админский пароль на чужом портале, что вполне понятно. Изнутри же, после развёртывания, агент уже никак сконфигурировать нельзя (можно только сменить его сетевые настройки). Здесь я предвижу сложности с особо осторожными заказчиками.
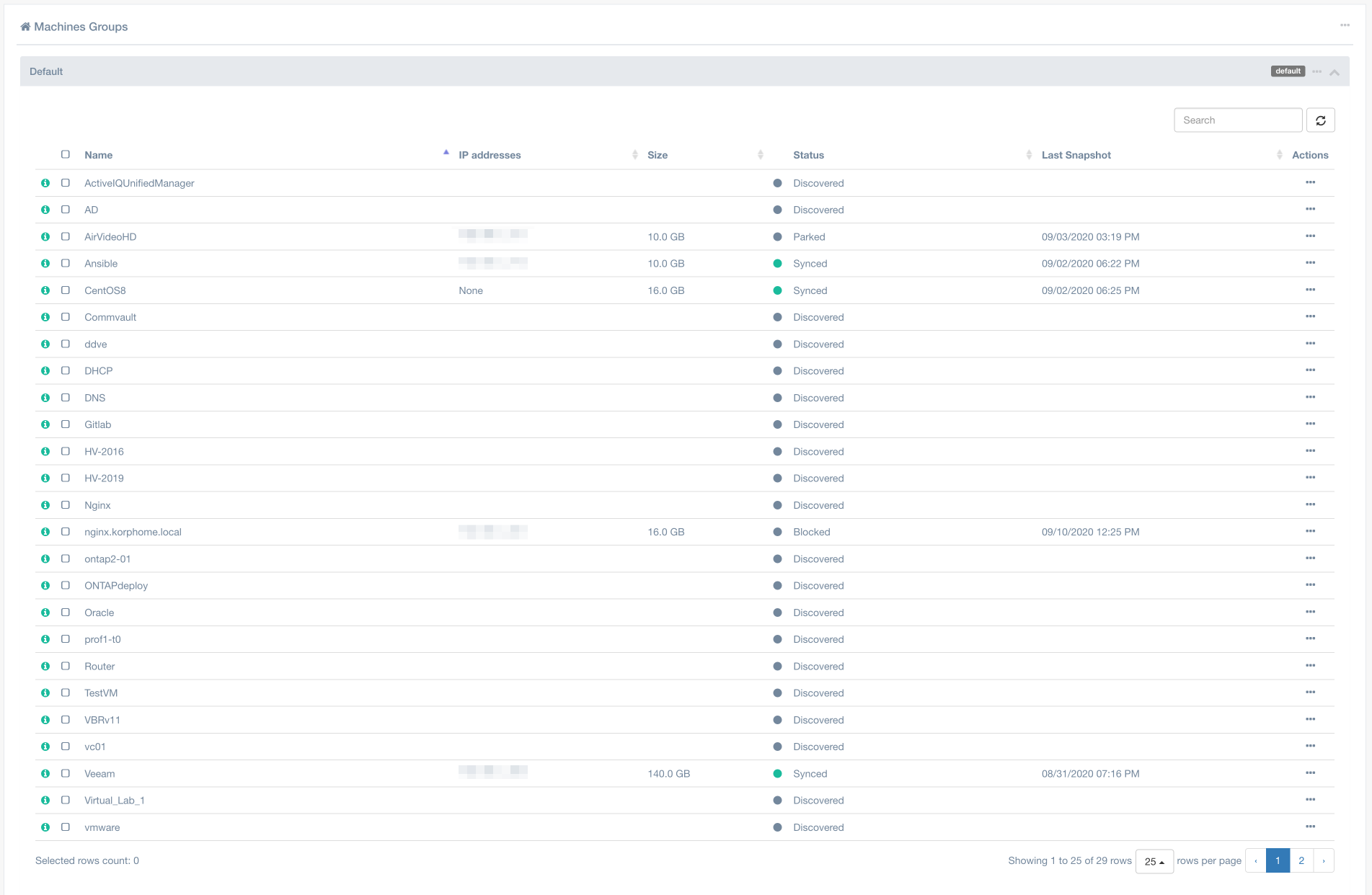
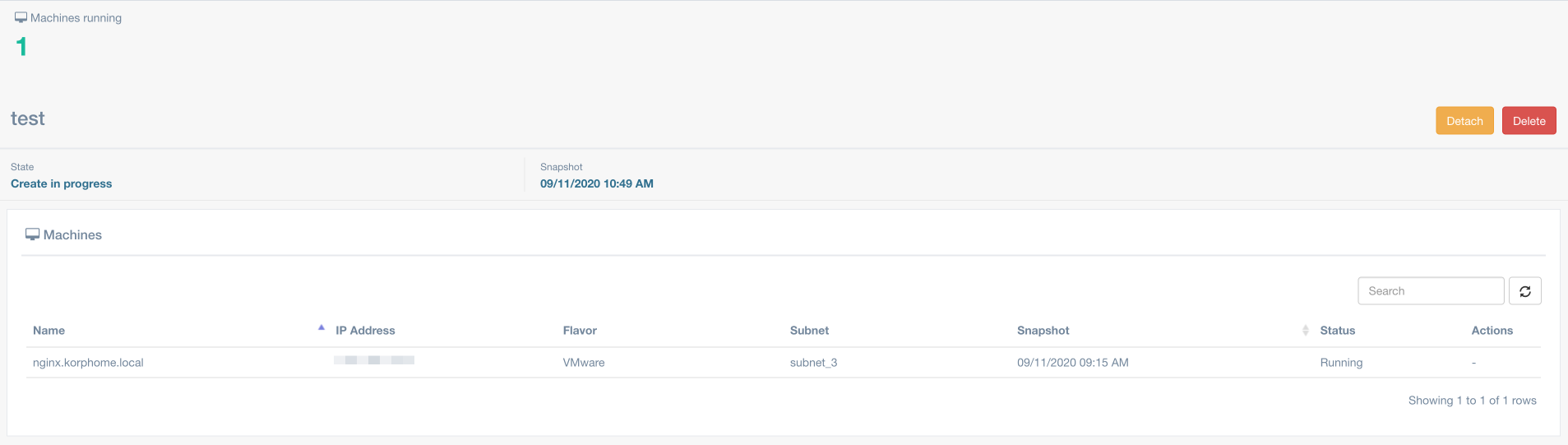
Итак, после установки агентов мы можем вернуться в панель Acura и увидеть все наши машины.

Поскольку я уже не первый день работаю с системой, у меня есть машины в различных состояниях. Все они у меня находятся в группе Default, но есть возможность создать отдельные группы и перенести в них машины, как вам это нужно. Это ни на что не влияет – лишь логическое представление данных и их группировка для более удобной работы. Первое и самое главное, что нам необходимо сделать после этого, – запустить процесс миграции. Мы можем это сделать как принудительно вручную, так и настроить расписание, в том числе и массово для всех машин сразу.

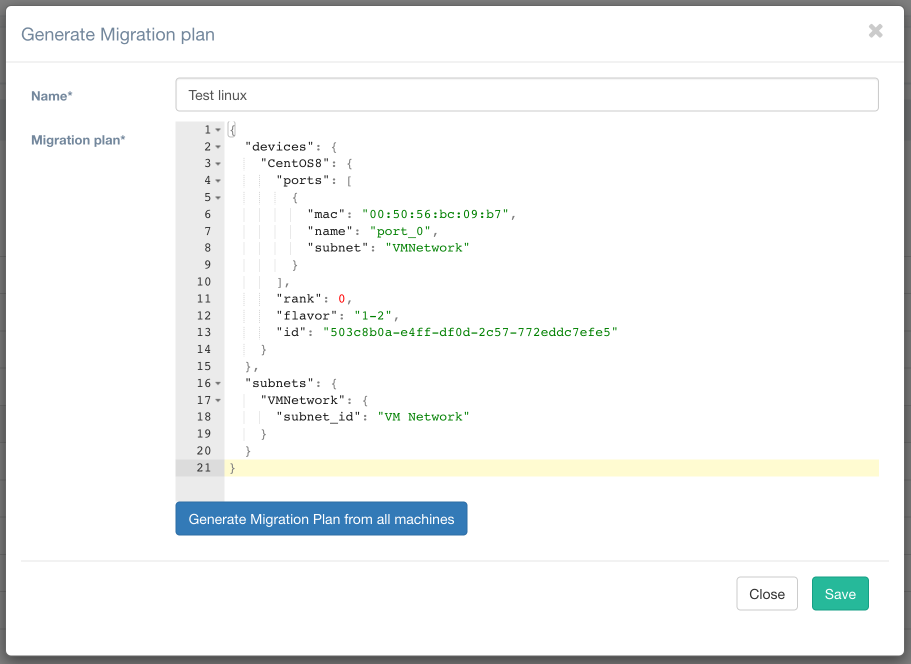
Напомню, что Hystax позиционировался как продукт для миграции. Поэтому нет ничего удивительного в том, что для запуска наших среплицированных машин нам необходимо создать DR-план. План можно составить для машин, которые уже находятся в состоянии Synced. Можно генерировать как для одной конкретной VM, так и для всех машин сразу.

Набор параметров при генерации DR-плана будет отличаться в зависимости от инфраструктуры, в которую вы будете мигрировать. Для VMware-среды доступен минимальный набор параметров. Также не поддерживается Re-IP для машин. В данном плане нас интересуют следующие моменты: в описании VM параметр «subnet»: «VMNetwork», где мы привязываем VM к конкретной сети в кластере. Rank – актуален при миграции нескольких VM, определяет очерёдность их запуска. Flavor – описывает конфигурацию VM, в данном случае – 1CPU, 2GB RAM. В секции subnets мы определяем, что «subnet»: «VMNetwork» ассоциирован с сетью «VM Network» VMware.
При создании DR-плана нет возможности «растащить» диски по разным датасторам. Они будут находиться на том же датасторе, который был определён для этого клиентского облака, и, если у вас диски разного класса, это может вызвать некоторые затруднения при старте машины, а после запуска и «отрыва» VM от Hystax, потребует ещё и отдельной миграции дисков на нужные датасторы. Дальше нам остаётся только запустить наш DR-план и дождаться, когда поднимутся наши машины. Процесс конвертации P2V/V2V также занимает время. На самой большой моей тестовой машине в 100Гб с тремя дисками это заняло максимум 10 минут.

После этого следует проверить запущенную ВМ, сервисы на ней, консистентность данных и провести прочие проверки.
Дальше у нас есть два пути:
- Delete – удалить запущенный DR-план. Это действие просто погасит запущенную VM. Данные реплики никуда не денутся.
- Detach – оторвать реплицированную машину от Acura, т.е. фактически завершить процесс миграции.
Плюсы решения:
- простота установки и настройки как со стороны клиента, так и со стороны провайдера;
- простота настройки миграции, создания DR-плана и запуска реплик;
- поддержка и разработчики довольно оперативно реагируют на найденные проблемы и устраняют их при помощи обновлений платформы или агентов.
Минусы
- Недостаточная поддержка Vmware.
- Отсутствие какого-либо квотирования для тенантов со стороны платформы.
Также я составил Feature Request, который мы передали вендору:
- мониторинг использования и деплой из консоли управления Acura для Cloud агентов;
- наличие квот для тенантов;
- возможность ограничения количества одновременных репликаций и скорости для каждого тенанта;
- поддержка VMware vCloud Director;
- поддержка ресурс пулов (было реализовано во время проведения тестирования);
- возможность настройки VMware-агента со стороны самого агента, без внесения учётных данных от клиентской инфраструктуры в панели Acura;
- «визуализация» процесса запуска VM при запуске DR-плана.
Единственное, что у меня вызвало большие нарекания – документация. Я не очень люблю «чёрные коробки» и предпочитаю, когда есть подробная документация о том, как работает продукт внутри. И если для AWS и OpenStack продукт описан ещё более-менее, то для VMware документации крайне мало.
Есть Installation Guide, который описывает только развёртывание панели Acura, и где нет ни слова о том, что нужен ещё и Cloud-агент. Есть полный набор спецификаций по продукту, что хорошо. Есть документация, которая описывает настройку «от и до» на примере AWS и OpenStack (хотя она мне больше напоминает пост в блоге), и есть совсем небольшая Knowledge Base.
В целом, это не совсем тот формат документации, к которому я привык, скажем, у более крупных вендоров, поэтому мне было не совсем комфортно. При этом ответы о некоторых нюансах работы системы «внутри» я так и не отыскал в этой документации – очень много вопросов приходилось уточнять у технической поддержки, и это довольно сильно затягивало процесс развёртывания стенда и проведения тестирования.
Подводя итог, я могу сказать, что в целом продукт и подход компании к реализации задачи мне понравились. Да, есть недоработки, есть действительно критичная недостаточность функционала (в связке с VMware). Видно, что, в первую очередь, компания ориентируется всё-таки на публичные облака, в частности AWS, и для кого-то этого будет достаточно. Наличие такого простого и удобного продукта сегодня, когда многие компании выбирают мультиоблачную стратегию, крайне важно. Учитывая гораздо более низкую цену по сравнению с конкурентами, это делает продукт крайне привлекательным.
Мы ищем себе в команду ведущего инженера систем мониторинга. Может быть, это именно вы?
===========
Источник:
habr.com
===========
Похожие новости:
- [Microsoft SQL Server, Администрирование баз данных, Резервное копирование] MS SQL Server: BACKUP на стероидах
- [Matlab, Инженерные системы, Резервное копирование, Софт, Управление продуктом] SimInTech — первая среда моделирования в России, импортозамещение, конкуренция с MATLAB
- [Виртуализация, Облачные вычисления] Лицом к разработчикам: модернизировать частное облако
- [Системное администрирование, Настройка Linux, Анализ и проектирование систем, Резервное копирование] Восстановление данных в современной инфраструктуре: как один админ бэкапы настраивал
- [Системное администрирование, IT-инфраструктура, Серверное администрирование, Резервное копирование] Veeam Log Diving: компоненты и глоссарий
- [Управление персоналом, Управление проектами] Добрые кубики, или Как дать обратную связь коллегам и кофемашине
- [Open source, Интернет вещей, Облачные сервисы, Разработка для интернета вещей] Знакомство с Node-RED и потоковое программирование в Yandex IoT Core
- [Визуализация данных, Конференции, Облачные вычисления, Облачные сервисы] Yandex Scale 2020: обсуждаем главные запуски и события в прямом эфире
- [*nix, IT-инфраструктура, Виртуализация, Облачные вычисления] Opennebula. Короткие записки
- [IT-инфраструктура, Восстановление данных, Облачные сервисы, Резервное копирование] Пусть хоть потоп, но 1С должна работать! Договариваемся с бизнесом о DR
Теги для поиска: #_vosstanovlenie_dannyh (Восстановление данных), #_oblachnye_vychislenija (Облачные вычисления), #_rezervnoe_kopirovanie (Резервное копирование), #_lanit (ланит), #_onlanta (онланта), #_hystax, #_oblaka (облака), #_oblachnye_reshenija (облачные решения), #_blog_kompanii_gk_lanit (
Блог компании ГК ЛАНИТ
), #_vosstanovlenie_dannyh (
Восстановление данных
), #_oblachnye_vychislenija (
Облачные вычисления
), #_rezervnoe_kopirovanie (
Резервное копирование
)
Вы не можете начинать темы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Текущее время: 18-Июн 23:16
Часовой пояс: UTC + 5
| Автор | Сообщение |
|---|---|
|
news_bot ®
Стаж: 8 лет 4 месяца |
|
|
Одним из молодых игроков на рынке решений Disaster Recovery является компания Hystax – российский стартап 2016 года. Поскольку тема аварийного восстановления очень популярна, и на рынке крайне высокая конкуренция, стартап решил сфокусироваться на миграции между различными облачными инфраструктурами. Продукт, позволяющий организовать простую и быструю миграцию в облако, был бы очень полезен и клиентам компании «Онланта» - пользователям Oncloud.ru. Так я и познакомился с Hystax и начал тестировать его возможности. А что из этого получилось, расскажу в этой статье.  Основной фишкой Hystax являются его широкая функциональность по поддержке различных платформ виртуализации, гостевых ОС и облачных сервисов, что даёт возможность переносить ваши рабочие нагрузки откуда угодно и куда угодно. Это позволяет создавать не только DR-решения для повышения отказоустойчивости сервисов, но и оперативно, гибко мигрировать ресурсы между различными площадками и гиперскейлерами для повышения экономии средств и выбора наилучшего решения под конкретный сервис в данный момент. Помимо платформ, перечисленных на заглавной картинке, компания также активно сотрудничает и с российскими облачными провайдерами: Yandex.Cloud, КРОК «Облачные сервисы», Mail.ru и многими другими. Также стоит отметить, что в 2020 году у компании появился R&D центр, располагающийся в Сколково. Выбор одного решения большим количеством игроков на рынке говорит о хорошей ценовой политике и высокой применимости продукта, что мы и решили проверить на практике. Итак, наша тестовая задача будет состоять из миграции с моей тестовой площадки VMware и физических машин на площадку провайдера также под управлением VMware. Да, есть множество решений, которые могут осуществить подобную миграцию, но мы рассматриваем Hystax как универсальное средство, а протестировать миграцию во всех возможных сочетаниях — просто нереальная задача. Да и облако Oncloud.ru построено именно на VMware, поэтому данная платформа как целевая интересует нас в большей степени. Далее я опишу основной принцип работы, который в целом не зависит от платформы, и VMware с любой стороны может быть заменена на платформу другого вендора. На первом этапе необходимо развернуть Hystax Acura, которая является панелью управления системы.  Она разворачивается из шаблона. Почему-то в нашем случае он был не совсем корректен и вместо рекомендуемых 8CPU, 16Gb разворачивался с вдвое меньшими ресурсами. Поэтому нужно не забыть их изменить, иначе контейнерами инфраструктура внутри VM, на которой всё и построено, просто не запустится и портал будет недоступен. В Deployment requirements подробно описаны требуемые ресурсы, а также порты для всех компонентов системы. И с заданием IP-адреса через шаблон также возникли трудности, так что меняли его из консоли. После этого можно перейти в веб-интерфейс админки и заполнить первоначальный мастер конфигурации.   Endpoint – IP или FQDN нашего vCenter. Login и Password – тут понятно. Target ESXi hostname – один из хостов нашего кластера, на который будет производиться репликация. Target datastore – один из датасторов нашего кластера, на который будет производится репликация. Hystax Acura Control Panel Public IP – адрес, по которому будет доступна панель управления. Требуется небольшое уточнение по хосту и датастору. Дело в том, что репликация Hystax работает на уровне хоста и датастора. Дальше я расскажу, каким образом можно для тенанта сменить хост и датастор, но проблема в другом. Hystax не поддерживает работу с ресурс пулами, т.е. реплика всегда будет происходить в корень кластера (во время написания этого материала ребята из Hystax выпустили обновлённую версию, где быстро внедрили мой feature request по поводу поддержки ресурс-пулов). Также не поддерживается и vCloud Director, т.е. если, как в моём случае, у тенанта нет админских прав на весь кластер, а только на конкретный ресурс-пул, и мы дали доступ к Hystax, то он сможет самостоятельно среплицировать и запустить эти ВМ, но он не сможет их увидеть в инфраструктуре VMware, к которой у него есть доступ и, соответственно, дальше управлять виртуальными машинами. Необходимо, чтобы администратор кластера переместил VM в нужный ресурсный пул или импортировал в vCloud Director. Почему я так акцентирую внимание на этих моментах? Потому что, насколько мне понятна концепция продукта, заказчик должен иметь возможность самостоятельно реализовать любую миграцию или DR при помощи панели Acura. Но пока поддержка VMware немного отстаёт по своему уровню от поддержки того же OpenStack, где подобные механизмы уже реализованы. Но вернёмся к развёртыванию. Первым делом, после первоначальной настройки панели, нам необходимо создать первого тенанта в нашей системе.  Все поля тут понятны, расскажу только про поле Cloud. У нас уже есть «дефолтное» облако, которое мы создали при первоначальном конфигурировании. Но если мы хотим иметь возможность класть каждый тенант на собственный датастор и в собственный ресурс-пул, мы можем это реализовать посредством создания отдельных облаков для каждого из наших заказчиков.  В форме добавления нового облака мы указываем те же параметры, что и при первоначальном конфигурировании (можем использовать даже тот же хост), указываем нужный для конкретного заказчика датастор, а теперь в дополнительных параметрах мы можем уже индивидуально указать необходимый ресурс-пул {«resource_pool»: «YOUR_POOL_NAME»} Как вы могли заметить, в форме создания тенанта нет ничего про выделение ресурсов или какие-то квоты – ничего этого в системе нет. Ограничить тенанта в количестве одновременных реплик, количестве машин для репликации или по какими-то иным параметрам нельзя. Итак, мы создали первого тенанта. Теперь есть не совсем логичная, но обязательная вещь – установка Cloud-агента. Нелогична она, поскольку агент скачивается на странице конкретного кастомера.  При этом он не привязывается к созданному тенанту, и через него будут работать все наши заказчики (или через несколько, если мы их задеплоим). Один агент поддерживает 10 одновременных сессий. За одну сессию считается одна машина. При этом не важно, какое у неё количество дисков. На сегодняшний день механизма для масштабирования агентов в самой Acura под VMware нет. Есть и ещё один неприятный момент – мы не имеем возможности из панели Acura посмотреть на «утилизацию» этого агента, чтобы сделать вывод, нужно ли нам развернуть ещё или текущей инсталляции достаточно. В итоге стенд выглядит следующим образом:  Следующим этапом для доступа к порталу нашего кастомера необходимо создать учётную запись (а предварительно ещё и роль, которая будет применяться к данному пользователю).   Теперь наш заказчик может пользоваться порталом самостоятельно. Всё, что ему необходимо сделать, – скачать с портала агентов и установить на своей стороне. Существует три вида агентов: Linux, Windows и VMware.  Первые два ставятся на физику или на виртуальные машины на любом гипервизоре, отличном от VMware. Здесь не требуется дополнительно ничего конфигурировать, агент скачивается и уже знает, куда нужно стучаться, и буквально через минуту машину будет видно в панели Acura. С агентом VMware ситуация чуть более сложная. Проблема в том, что агент для VMware также скачивается с портала уже подготовленный и имеющий в себе необходимую конфигурацию. Но агенту VMware помимо знания о нашем портале Acura необходимо знать ещё и о системе виртуализации, на которой он будет развёрнут.  Собственно, эти данные система и попросит нас указать при первом скачивании агента VMware. Проблема в том, что в наш век всеобщей любви к безопасности далеко не все захотят указывать свой админский пароль на чужом портале, что вполне понятно. Изнутри же, после развёртывания, агент уже никак сконфигурировать нельзя (можно только сменить его сетевые настройки). Здесь я предвижу сложности с особо осторожными заказчиками. Итак, после установки агентов мы можем вернуться в панель Acura и увидеть все наши машины.  Поскольку я уже не первый день работаю с системой, у меня есть машины в различных состояниях. Все они у меня находятся в группе Default, но есть возможность создать отдельные группы и перенести в них машины, как вам это нужно. Это ни на что не влияет – лишь логическое представление данных и их группировка для более удобной работы. Первое и самое главное, что нам необходимо сделать после этого, – запустить процесс миграции. Мы можем это сделать как принудительно вручную, так и настроить расписание, в том числе и массово для всех машин сразу.  Напомню, что Hystax позиционировался как продукт для миграции. Поэтому нет ничего удивительного в том, что для запуска наших среплицированных машин нам необходимо создать DR-план. План можно составить для машин, которые уже находятся в состоянии Synced. Можно генерировать как для одной конкретной VM, так и для всех машин сразу.  Набор параметров при генерации DR-плана будет отличаться в зависимости от инфраструктуры, в которую вы будете мигрировать. Для VMware-среды доступен минимальный набор параметров. Также не поддерживается Re-IP для машин. В данном плане нас интересуют следующие моменты: в описании VM параметр «subnet»: «VMNetwork», где мы привязываем VM к конкретной сети в кластере. Rank – актуален при миграции нескольких VM, определяет очерёдность их запуска. Flavor – описывает конфигурацию VM, в данном случае – 1CPU, 2GB RAM. В секции subnets мы определяем, что «subnet»: «VMNetwork» ассоциирован с сетью «VM Network» VMware. При создании DR-плана нет возможности «растащить» диски по разным датасторам. Они будут находиться на том же датасторе, который был определён для этого клиентского облака, и, если у вас диски разного класса, это может вызвать некоторые затруднения при старте машины, а после запуска и «отрыва» VM от Hystax, потребует ещё и отдельной миграции дисков на нужные датасторы. Дальше нам остаётся только запустить наш DR-план и дождаться, когда поднимутся наши машины. Процесс конвертации P2V/V2V также занимает время. На самой большой моей тестовой машине в 100Гб с тремя дисками это заняло максимум 10 минут.  После этого следует проверить запущенную ВМ, сервисы на ней, консистентность данных и провести прочие проверки. Дальше у нас есть два пути:
Плюсы решения:
Минусы
Также я составил Feature Request, который мы передали вендору:
Единственное, что у меня вызвало большие нарекания – документация. Я не очень люблю «чёрные коробки» и предпочитаю, когда есть подробная документация о том, как работает продукт внутри. И если для AWS и OpenStack продукт описан ещё более-менее, то для VMware документации крайне мало. Есть Installation Guide, который описывает только развёртывание панели Acura, и где нет ни слова о том, что нужен ещё и Cloud-агент. Есть полный набор спецификаций по продукту, что хорошо. Есть документация, которая описывает настройку «от и до» на примере AWS и OpenStack (хотя она мне больше напоминает пост в блоге), и есть совсем небольшая Knowledge Base. В целом, это не совсем тот формат документации, к которому я привык, скажем, у более крупных вендоров, поэтому мне было не совсем комфортно. При этом ответы о некоторых нюансах работы системы «внутри» я так и не отыскал в этой документации – очень много вопросов приходилось уточнять у технической поддержки, и это довольно сильно затягивало процесс развёртывания стенда и проведения тестирования. Подводя итог, я могу сказать, что в целом продукт и подход компании к реализации задачи мне понравились. Да, есть недоработки, есть действительно критичная недостаточность функционала (в связке с VMware). Видно, что, в первую очередь, компания ориентируется всё-таки на публичные облака, в частности AWS, и для кого-то этого будет достаточно. Наличие такого простого и удобного продукта сегодня, когда многие компании выбирают мультиоблачную стратегию, крайне важно. Учитывая гораздо более низкую цену по сравнению с конкурентами, это делает продукт крайне привлекательным. Мы ищем себе в команду ведущего инженера систем мониторинга. Может быть, это именно вы? =========== Источник: habr.com =========== Похожие новости:
Блог компании ГК ЛАНИТ ), #_vosstanovlenie_dannyh ( Восстановление данных ), #_oblachnye_vychislenija ( Облачные вычисления ), #_rezervnoe_kopirovanie ( Резервное копирование ) |
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Вы не можете начинать темы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Текущее время: 18-Июн 23:16
Часовой пояс: UTC + 5