[Разработка игр, Машинное обучение, Игры и игровые приставки] Применение машинного обучения в разработке игр (перевод)
Автор
Сообщение
news_bot ®
Стаж: 8 лет 4 месяца
Сообщений: 27286

Популярность многопользовательских онлайн-игр стремительно нарастает, они привлекают миллионы игроков по всему миру. Такая популярность также существенно повысила требования к гейм-дизайнерам, игроки ожидают, что игры будут сбалансированными и отшлифованными, ведь нет никакого интереса играть, если одна стратегия побеждает все остальные.
Для создания качественного игрового процесса гейм-дизайнеры обычно настраивают баланс игры итеративно:
- Выполняют нагрузочный тест тысячами плейтестинговых сессий, в которых участвуют тестеры
- Учитывают их отзывы и изменяют дизайн игры
- Повторяют этапы 1 и 2, пока результатом не будут довольны и тестеры, и гейм-дизайнеры
Этот процесс не только занимает много времени, но и неидеален — чем сложнее игра, тем проще незначительным недосмотрам привести к дисбалансу. Когда в играх есть множество различных ролей с десятками взаимосвязанных навыков, всё это сильно усложняет нахождение нужного баланса.
В представленной методике для настройки игрового баланса используется машинное обучение (machine learning, ML) при помощи обучения моделей, применяемых качестве плейтестеров. В этом переводе расскажем про методику на примере прототипа цифровой карточной игры Chimera, которую ранее демонстрировали в качестве испытательного полигона для генерируемых машинным обучением картин. Проводя при помощи обученных агентов миллионы симуляций с целью сбора данных, эта методика тестирования игр на основе ML позволяет гейм-дизайнерам эффективнее повышать интересность и баланс игр.
Chimera
Мы разрабатывали Chimera как прототип, при создании которого активно применялось машинное обучение. Мы намеренно спроектировали правила игры так, чтобы расширить пространство возможностей и усложнить создание ИИ традиционным способом, «вручную».
Геймплей Chimera основывается на использовании химер — «гибридов» различных существ, которых игроки усиливают и развивают. Цель игры — победить химеру противника. Основные принципы дизайна игры таковы:
- Игроки могут:
- играть существами, способными атаковать (с помощью их характеристики атаки) или быть атакованными (что снижает их характеристику здоровья), или
- использовать заклинания, создающими особые эффекты.
- Существа призываются в биомы ограниченного размера, физически располагаемые на пространстве игрового поля. Каждое существо имеет предпочтительный биом и получает повторный урон при размещении на неправильном биоме или если занимает в биоме лишнее место.
- Игрок управляет одной химерой, начинающей с базового состояния «яйца». Она может эволюционировать и усиливаться, поглощая существ. Для этого игрок также должен получить определённое количество энергии связи, которая генерируется из различных геймплейных механик.
- Игра заканчивается, когда игрок снизит здоровье химеры противника до 0.
Обучаемся играть в Chimera
Поскольку Chimera является карточной игрой с неполной информацией в большом пространстве состояний, мы ожидали, что ML-модели будет сложно обучиться ей, особенно потому, что мы решили использовать относительно простую модель. Мы использовали методику, созданную под влиянием использовавшихся в предыдущих агентах-игроках, например AlphaGo, в которых свёрточная нейронная сеть (CNN) обучается прогнозировать вероятность выигрыша в произвольном игровом состоянии. Немного обучив модель на играх, где выбирались случайные ходы, мы заставили агентов играть друг против друга, итеративно собирая игровые данные, которые затем использовались для обучения нового агента. С каждой итерацией качество данных обучения улучшалось, как и способность агента играть.

Результаты ML-агента в игре против наилучшего созданного вручную ИИ в процессе обучения. Изначальный ML-агент (версия 0) выбирал ходы случайно.
При выборе описания игрового состояния, передаваемого на вход модели, мы выяснили, что наилучшие результаты даёт передача сети CNN закодированного «образа»; она оказалась лучше, чем все процедурные агенты-бенчмарки и другие типы сетей (например, полносвязанные). Выбранная архитектура модели достаточно мала, поэтому выполняется на ЦП за разумное время, что позволило нам скачать веса модели и запускать агент напрямую в клиенте игры Chimera при помощи Unity Barracuda.

Пример описания игрового состояния, использовавшегося для обучения нейронной сети.

Кроме принятия решений за игровой ИИ мы также использовали модель для отображения оценки вероятности победы игрока в течение игры.
Балансировка Chimera
Такая методика позволила нам симулировать на миллионы игр больше, чем способны сыграть живые игроки за тот же промежуток времени. После сбора данных из игр, сыгранных наиболее эффективными агентами, мы проанализировали результаты, чтобы найти дисбаланс между двумя спроектированными нами колодами игроков.
Колода Evasion Link Gen была составлена из заклинаний и существ со способностями, генерирующими дополнительную энергию связи, которая применяется для развития химеры игрока. Также она содержала заклинания, позволяющие существам уклоняться от атак. Колода Damage-Heal содержала существ различной силы с заклинаниями, в основном предназначенными для лечения и нанесения незначительного урона. Хотя мы проектировали эти колоды так, чтобы они имели одинаковую силу, колода Evasion Link Gen выигрывала в 60% случаев, когда играла против колоды Damage-Heal.
Когда мы собрали различную статистику, связанную с биомами, существами, заклинаниями и эволюцией химер, нам сразу же стали очевидными два аспекта:
- Развитие химеры предоставляет явное преимущество — агент выигрывал большинство игр, в которых он развивал свою химеру больше, чем противник. Однако среднее количество эволюций за игру не соответствовало нашим ожиданиям. Чтобы сделать их более ключевой игровой механикой, мы хотели увеличить общее среднее количество эволюций, сохраняя при этом стратегичность их применения.
- Существо T-Rex оказалось слишком сильным. Его появление сильно коррелировало с победами, и модель всегда играла карту T-Rex, вне зависимости от потерь из-за вызова существа в неправильном или переполненном биоме.
Исходя из этих наблюдений, мы внесли в игру некоторые улучшения. Чтобы сделать эволюцию химер базовым механизмом игры, мы снизили количество энергии связи, необходимой для развития химеры, с 3 до 1 единицы. Также мы добавили период «отдыха» существу T-Rex, удвоив время, необходимое ему для восстановления после любого его действия.
Изменив правила и повторив нашу процедуру обучения «игры с самим собой», мы выяснили, что эти обновления переместили игру в нужном направлении — среднее количество эволюций на игру увеличилось, а доминирование T-Rex исчезло.

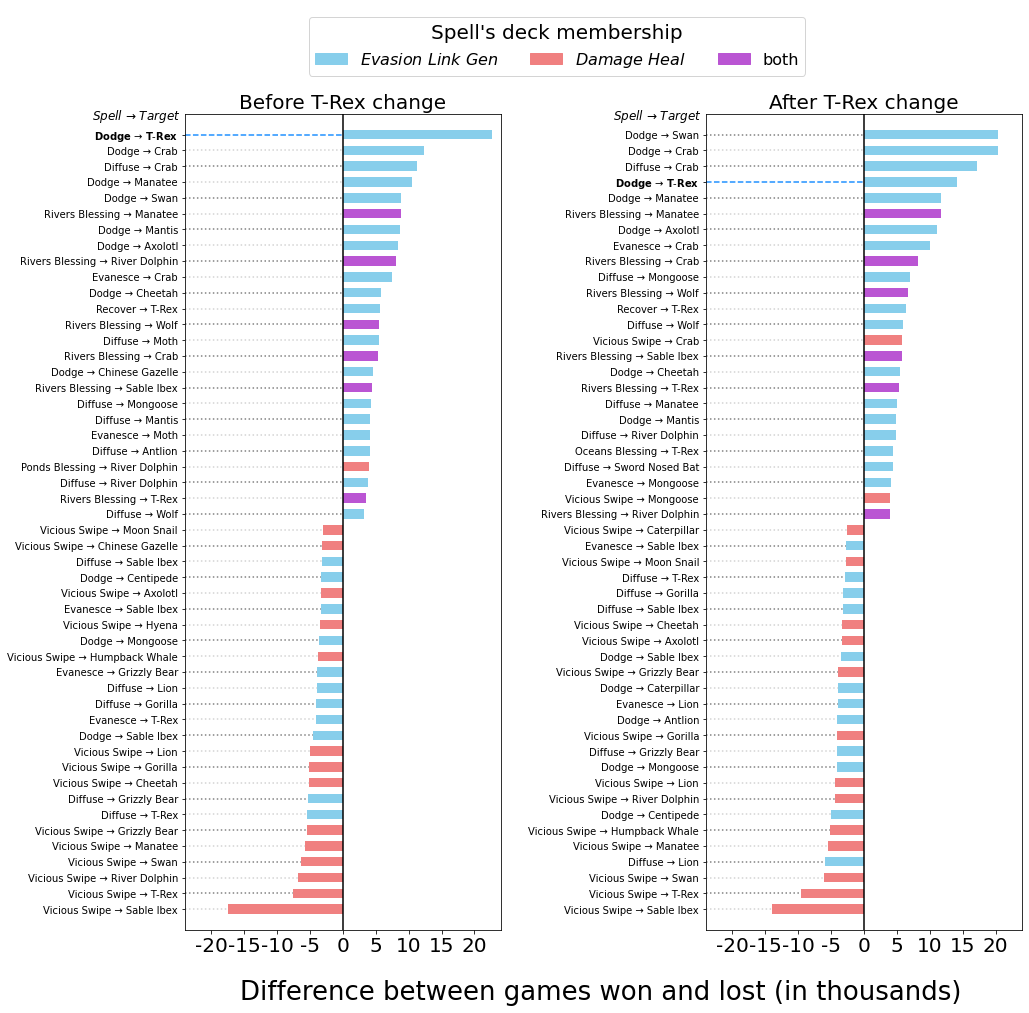
Пример сравнения воздействия T-Rex до и после балансировки. На графиках показано количество выигранных (или проигранных) игр, когда колода начинает взаимодействие конкретных заклинаний (например, использование заклинания «Dodge» для обеспечения преимущества существа T-Rex). Слева: до изменений T-Rex сильно влиял на каждую изучаемую метрику — наибольшая частота выживания, наибольшая вероятность вызова с игнорированием негативных воздействий, самое часто поглощаемое существо во время победных партий. Справа: после изменений излишняя мощь T-Rex намного снизилась.
Ослабив T-Rex, мы успешно снизили зависимость колоды Evasion Link Gen от слишком мощного существа. Но даже после этого соотношение побед между колодами осталось 60/40, а не 50/50. Внимательное изучение логов отдельных игр выявило, что геймплей часто был намного менее стратегичным, чем нам бы хотелось. Выполнив поиск по собранным данным, мы выявили ещё несколько областей, требующих изменений.
Для начала мы увеличили исходное здоровье обоих игроков, а также величину здоровья, которое можно восстановить заклинаниями излечения. Это должно было стимулировать к более долгим партиям, позволяющим развиваться более разнообразному множеству стратегий. В частности, это позволило колоде Damage-Heal выживать достаточно долго, чтобы пользоваться преимуществом её стратегии лечения. Чтобы стимулировать агента к правильному вызову существ и стратегическому размещению их в биомах, мы увеличили наказания за размещение существ в неправильных или переполненных биомах. Также мы уменьшили разрыв между самыми сильными и самыми слабыми существами с помощью мелких изменений атрибутов.
После внесения новых изменений мы получили окончательные характеристики игрового баланса для этих двух колод:
Колода
Среднее количество эволюций за партию
(до →после)
Процент побед (1 миллион игр)
(до → после)
Evasion Link Gen
1,54 → 2,16
59,1% → 49,8%
Damage Heal
0,86 → 1,76
40,9% → 50,2%
Вывод
Обычно на выявление дисбаланса в новых прототипах игр требуются месяцы плейтестинга. При использовании нашей методики мы смогли не только выявить потенциальные источники дисбаланса, но и за считанные дни внести изменения, позволяющие смягчить их воздействие. Мы выяснили, что относительно простой нейронной сети достаточно, чтобы достичь высокой эффективности игры против игроков и традиционного игрового ИИ. Таких агентов можно использовать различными способами, например, для тренировки новых игроков или для выявления неожиданных стратегий. Мы надеемся, эта работа вдохновит на дальнейшие исследования возможностей машинного обучения в сфере разработки игр.
На правах рекламы
Мощные VDS с защитой от DDoS-атак и новейшим железом. Всё это про наши эпичные серверы. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.

оригинал
===========
Источник:
habr.com
===========
===========
Автор оригинала: Ji Hun Kim & Richard Wu
===========Похожие новости:
- [Программирование, IT-инфраструктура, Big Data, R] IT Service Health Monitoring средствами R. Взгляд под иным углом
- [Венчурные инвестиции, Развитие стартапа, Финансы в IT, IT-компании] Новости IT и инвестиций: Apple предустановит Яндекс и Mail.Ru, государство хочет следить за машинами
- [Python, Машинное обучение, Data Engineering] Как обойти капчу Гугл
- [Разработка веб-сайтов, JavaScript, Программирование, HTML] Красивое радио для браузера
- [Облачные вычисления, Конференции, Искусственный интеллект, Здоровье, IT-компании] Открылась регистрация на участие в онлайн-конференции NVIDIA GTC
- [Высокая производительность, Машинное обучение, Производство и разработка электроники] Applied Materials подключила ИИ к проверке пластин при изготовлении кристаллов микросхем
- [Машинное обучение, Искусственный интеллект] Как быть, если ваша нейросеть включает в генерируемые тексты реальные телефонные номера людей? (перевод)
- [Big Data, Машинное обучение] Как управлять проектами машинного обучения и data science (перевод)
- [Работа с 3D-графикой, Разработка игр, Дизайн игр, Научно-популярное] Зеркала в Duke Nukem 3D
- [Разработка веб-сайтов, JavaScript, Программирование, HTML] Фреймворк Webix Jet глазами новичка. Часть 1. Композиция и навигация
Теги для поиска: #_razrabotka_igr (Разработка игр), #_mashinnoe_obuchenie (Машинное обучение), #_igry_i_igrovye_pristavki (Игры и игровые приставки), #_machine_learning, #_ml, #_razrabotka_igr (разработка игр), #_chimera, #_google, #_blog_kompanii_vdsina.ru (
Блог компании VDSina.ru
), #_razrabotka_igr (
Разработка игр
), #_mashinnoe_obuchenie (
Машинное обучение
), #_igry_i_igrovye_pristavki (
Игры и игровые приставки
)
Вы не можете начинать темы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Текущее время: 19-Июн 06:26
Часовой пояс: UTC + 5
| Автор | Сообщение |
|---|---|
|
news_bot ®
Стаж: 8 лет 4 месяца |
|
 Популярность многопользовательских онлайн-игр стремительно нарастает, они привлекают миллионы игроков по всему миру. Такая популярность также существенно повысила требования к гейм-дизайнерам, игроки ожидают, что игры будут сбалансированными и отшлифованными, ведь нет никакого интереса играть, если одна стратегия побеждает все остальные. Для создания качественного игрового процесса гейм-дизайнеры обычно настраивают баланс игры итеративно:
Этот процесс не только занимает много времени, но и неидеален — чем сложнее игра, тем проще незначительным недосмотрам привести к дисбалансу. Когда в играх есть множество различных ролей с десятками взаимосвязанных навыков, всё это сильно усложняет нахождение нужного баланса. В представленной методике для настройки игрового баланса используется машинное обучение (machine learning, ML) при помощи обучения моделей, применяемых качестве плейтестеров. В этом переводе расскажем про методику на примере прототипа цифровой карточной игры Chimera, которую ранее демонстрировали в качестве испытательного полигона для генерируемых машинным обучением картин. Проводя при помощи обученных агентов миллионы симуляций с целью сбора данных, эта методика тестирования игр на основе ML позволяет гейм-дизайнерам эффективнее повышать интересность и баланс игр. Chimera Мы разрабатывали Chimera как прототип, при создании которого активно применялось машинное обучение. Мы намеренно спроектировали правила игры так, чтобы расширить пространство возможностей и усложнить создание ИИ традиционным способом, «вручную». Геймплей Chimera основывается на использовании химер — «гибридов» различных существ, которых игроки усиливают и развивают. Цель игры — победить химеру противника. Основные принципы дизайна игры таковы:
Обучаемся играть в Chimera Поскольку Chimera является карточной игрой с неполной информацией в большом пространстве состояний, мы ожидали, что ML-модели будет сложно обучиться ей, особенно потому, что мы решили использовать относительно простую модель. Мы использовали методику, созданную под влиянием использовавшихся в предыдущих агентах-игроках, например AlphaGo, в которых свёрточная нейронная сеть (CNN) обучается прогнозировать вероятность выигрыша в произвольном игровом состоянии. Немного обучив модель на играх, где выбирались случайные ходы, мы заставили агентов играть друг против друга, итеративно собирая игровые данные, которые затем использовались для обучения нового агента. С каждой итерацией качество данных обучения улучшалось, как и способность агента играть.  Результаты ML-агента в игре против наилучшего созданного вручную ИИ в процессе обучения. Изначальный ML-агент (версия 0) выбирал ходы случайно. При выборе описания игрового состояния, передаваемого на вход модели, мы выяснили, что наилучшие результаты даёт передача сети CNN закодированного «образа»; она оказалась лучше, чем все процедурные агенты-бенчмарки и другие типы сетей (например, полносвязанные). Выбранная архитектура модели достаточно мала, поэтому выполняется на ЦП за разумное время, что позволило нам скачать веса модели и запускать агент напрямую в клиенте игры Chimera при помощи Unity Barracuda.  Пример описания игрового состояния, использовавшегося для обучения нейронной сети.  Кроме принятия решений за игровой ИИ мы также использовали модель для отображения оценки вероятности победы игрока в течение игры. Балансировка Chimera Такая методика позволила нам симулировать на миллионы игр больше, чем способны сыграть живые игроки за тот же промежуток времени. После сбора данных из игр, сыгранных наиболее эффективными агентами, мы проанализировали результаты, чтобы найти дисбаланс между двумя спроектированными нами колодами игроков. Колода Evasion Link Gen была составлена из заклинаний и существ со способностями, генерирующими дополнительную энергию связи, которая применяется для развития химеры игрока. Также она содержала заклинания, позволяющие существам уклоняться от атак. Колода Damage-Heal содержала существ различной силы с заклинаниями, в основном предназначенными для лечения и нанесения незначительного урона. Хотя мы проектировали эти колоды так, чтобы они имели одинаковую силу, колода Evasion Link Gen выигрывала в 60% случаев, когда играла против колоды Damage-Heal. Когда мы собрали различную статистику, связанную с биомами, существами, заклинаниями и эволюцией химер, нам сразу же стали очевидными два аспекта:
Исходя из этих наблюдений, мы внесли в игру некоторые улучшения. Чтобы сделать эволюцию химер базовым механизмом игры, мы снизили количество энергии связи, необходимой для развития химеры, с 3 до 1 единицы. Также мы добавили период «отдыха» существу T-Rex, удвоив время, необходимое ему для восстановления после любого его действия. Изменив правила и повторив нашу процедуру обучения «игры с самим собой», мы выяснили, что эти обновления переместили игру в нужном направлении — среднее количество эволюций на игру увеличилось, а доминирование T-Rex исчезло.  Пример сравнения воздействия T-Rex до и после балансировки. На графиках показано количество выигранных (или проигранных) игр, когда колода начинает взаимодействие конкретных заклинаний (например, использование заклинания «Dodge» для обеспечения преимущества существа T-Rex). Слева: до изменений T-Rex сильно влиял на каждую изучаемую метрику — наибольшая частота выживания, наибольшая вероятность вызова с игнорированием негативных воздействий, самое часто поглощаемое существо во время победных партий. Справа: после изменений излишняя мощь T-Rex намного снизилась. Ослабив T-Rex, мы успешно снизили зависимость колоды Evasion Link Gen от слишком мощного существа. Но даже после этого соотношение побед между колодами осталось 60/40, а не 50/50. Внимательное изучение логов отдельных игр выявило, что геймплей часто был намного менее стратегичным, чем нам бы хотелось. Выполнив поиск по собранным данным, мы выявили ещё несколько областей, требующих изменений. Для начала мы увеличили исходное здоровье обоих игроков, а также величину здоровья, которое можно восстановить заклинаниями излечения. Это должно было стимулировать к более долгим партиям, позволяющим развиваться более разнообразному множеству стратегий. В частности, это позволило колоде Damage-Heal выживать достаточно долго, чтобы пользоваться преимуществом её стратегии лечения. Чтобы стимулировать агента к правильному вызову существ и стратегическому размещению их в биомах, мы увеличили наказания за размещение существ в неправильных или переполненных биомах. Также мы уменьшили разрыв между самыми сильными и самыми слабыми существами с помощью мелких изменений атрибутов. После внесения новых изменений мы получили окончательные характеристики игрового баланса для этих двух колод: Колода Среднее количество эволюций за партию (до →после) Процент побед (1 миллион игр) (до → после) Evasion Link Gen 1,54 → 2,16 59,1% → 49,8% Damage Heal 0,86 → 1,76 40,9% → 50,2% Вывод Обычно на выявление дисбаланса в новых прототипах игр требуются месяцы плейтестинга. При использовании нашей методики мы смогли не только выявить потенциальные источники дисбаланса, но и за считанные дни внести изменения, позволяющие смягчить их воздействие. Мы выяснили, что относительно простой нейронной сети достаточно, чтобы достичь высокой эффективности игры против игроков и традиционного игрового ИИ. Таких агентов можно использовать различными способами, например, для тренировки новых игроков или для выявления неожиданных стратегий. Мы надеемся, эта работа вдохновит на дальнейшие исследования возможностей машинного обучения в сфере разработки игр. На правах рекламы Мощные VDS с защитой от DDoS-атак и новейшим железом. Всё это про наши эпичные серверы. Максимальная конфигурация — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.  оригинал =========== Источник: habr.com =========== =========== Автор оригинала: Ji Hun Kim & Richard Wu ===========Похожие новости:
Блог компании VDSina.ru ), #_razrabotka_igr ( Разработка игр ), #_mashinnoe_obuchenie ( Машинное обучение ), #_igry_i_igrovye_pristavki ( Игры и игровые приставки ) |
|
{kind=link}
Вы не можете начинать темы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Вы не можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
Вы не можете прикреплять файлы к сообщениям
Вы не можете скачивать файлы
Текущее время: 19-Июн 06:26
Часовой пояс: UTC + 5